关于正则化的文章是铺天盖地,其中绝大部分都在解释为什么L1或者L2正则化有利于产生稀疏解,防止过拟合?这个问题被讨论论证了N多次,大篇幅的文字叙述可以让读者了解到其背后的原理,但本文不走大众之路,从力求以动态图来直观解释正则化现象,从而让读者更深刻理解其正则的意义!
抛开理论推导验证环节,需要从文字上面理解的强烈推荐参考博文后面的链接文章,本文以实际例子来进行阐述,考虑L1正则化对二次损失函数权值的影响。
假设我们的损失函数:
带L1正则化的损失函数为:
其中 lambda为正则化因子,其值大小影响着x_1,x_2的变化,值越大,x_1,x_2就越趋向于0,从而产生稀疏解,典型的具有特征选择的作用。下面代码逐渐变化lambda的大小,分别画出L和J的损失函数和等值线图,红色点为对应lambda取特定值时候J的最小值。
1 | clear;clc;close all; |
中间求极值函数J的表述为:
1 | function f = myfun(x,lambda) |
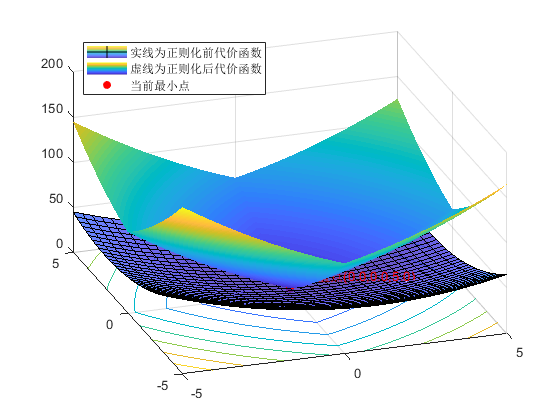
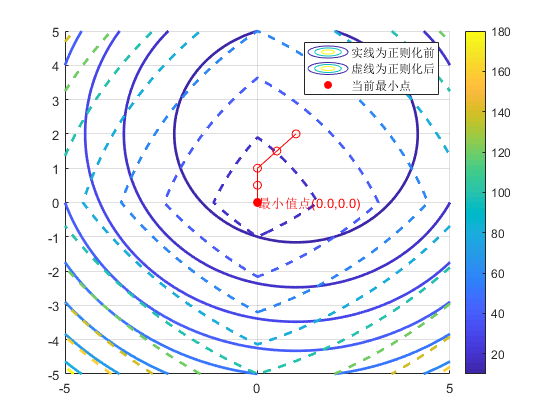
输出值为:
lambda:0,最小值点(1.0,2.0,0.0)
lambda:1,最小值点(0.5,1.5,2.5)
lambda:2,最小值点(0.0,1.0,4.0)
lambda:3,最小值点(0.0,0.5,4.8)
lambda:4,最小值点(0.0,0.0,5.0)
lambda:5,最小值点(0.0,0.0,5.0)
lambda:6,最小值点(0.0,0.0,5.0)
lambda:7,最小值点(0.0,0.0,5.0)
lambda:8,最小值点(0.0,0.0,5.0)
lambda:9,最小值点(0.0,0.0,5.0)
lambda:10,最小值点(0.0,0.0,5.0)
可以看出,当lambda=0时候,即没有进行正则化,和原损失函数一致,在点(1,2)处取得最小值0,随着lambda逐渐增大,lambda=4,x1,x2就被稀疏为0了,代价函数(损失函数)曲面会越来越尖,逐渐偏离原来(1,2)点。
reference: 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中正则化项L1和L2的直观理解
深入理解L1、L2正则化
l1正则与l2正则的特点是什么,各有什么优势?